We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. The group by clause is most often used along with the aggregate functions like MAX(), MIN(), COUNT(), SUM(), etc to get the summarized data from the table or multiple tables joined together. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc. Let us use the aggregate functions in the group by clause with multiple columns.
This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950. Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement.

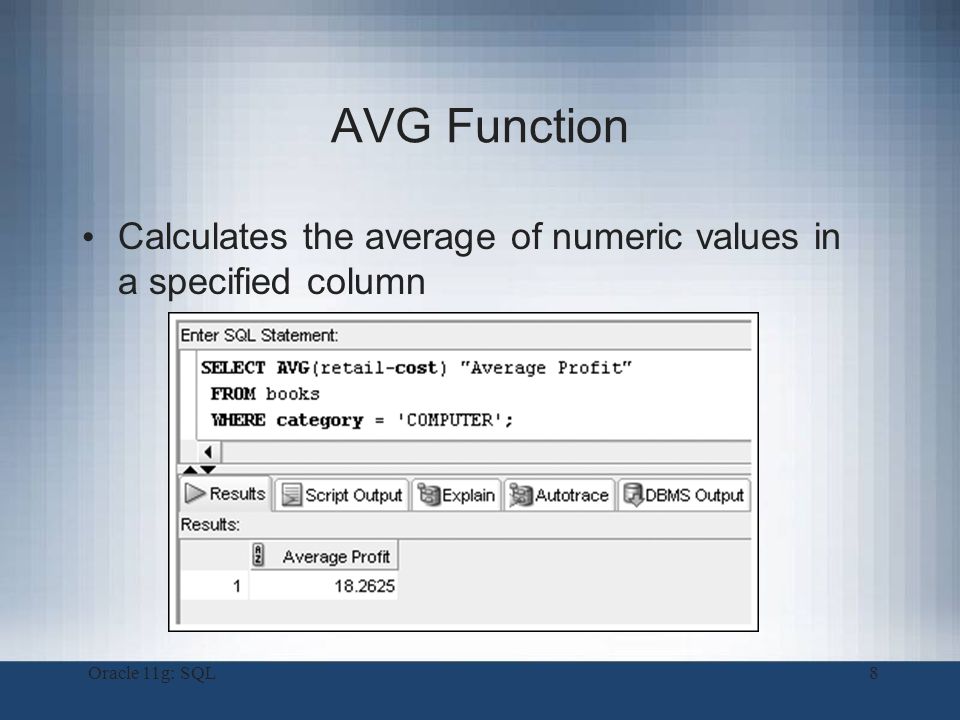
Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. Tables The tables that you wish to retrieve records from. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.
The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. This is the default behavior, if no modifier is provider. DESC sorts the result set in descending order by expression. There's an additional way to run aggregation over a table.
If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. There are times when you want to have SQL Server return an aggregated result set, instead of a detailed result set. SQL Server has the GROUP BY clause that provides you a way to aggregate your SQL Server data. The GROUP BY clause allows you to group data on a single column, multiple columns, or even expressions. In this article I will be discussing how to use the GROUP by clause to summarize your data.
You cannot test them as NULL values in join conditions or the WHERE clause to determine which rows to select. For example, you cannot add WHERE product IS NULL to the query to eliminate from the output all but the super-aggregate rows. The GROUP BY clause is used in the SELECT statement .Optionally it is used in conjunction with aggregate functions to produce summary reports from the database.

The queries that contain the GROUP BY clause are called grouped queries and only return a single row for every grouped item. The GROUP BY clause is used to group the rows based on a set of specified grouping expressions and compute aggregations on the group of rows based on one or more specified aggregate functions. Spark also supports advanced aggregations to do multiple aggregations for the same input record set via GROUPING SETS, CUBE, ROLLUP clauses. The grouping expressions and advanced aggregations can be mixed in the GROUP BY clause and nested in a GROUPING SETS clause.

See more details in the Mixed/Nested Grouping Analytics section. When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions .

In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both. The SQL GROUP BY statement appears in aggregate functions. It is used to collate the data you select from a query by a particular column. You can specify multiple columns which will be grouped using the GROUP BY statement. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.

The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. Use theSQL GROUP BYClause is to consolidate like values into a single row.

The group by returns a single row from one or more within the query having the same column values. Its main purpose is this work alongside functions, such as SUM or COUNT, and provide a means to summarize values. In the Group BY clause, the SELECT statement can use constants, aggregate functions, expressions, and column names.

If the WITH TOTALS modifier is specified, another row will be calculated. This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). GROUP BY clauses are common in queries that use aggregate functions such as MIN and MAX. The GROUP BY statement tells SQL how to aggregate the information in any non-aggregate column you have queried. When querying multiple tables, use aliases, and employ those aliases in your select statement, so the database doesn't need to parse which column belongs to which table.
Note that if you have columns with the same name across multiple tables, you will need to explicitly reference them with either the table name or alias. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. The GROUP BY clause divides the rows returned from the SELECTstatement into groups.
For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns. Group By in SQL helps us club together identical rows present in the columns of a table. This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary. Finally, following all other rows, an extra super-aggregate summary row appears showing the grand total for all years, countries, and products.

This row has the year, country, and products columns set to NULL. Following each set of rows for a given year, an extra super-aggregate summary row appears showing the total for all countries and products. These rows have the country and productscolumns set to NULL.

Though it's not required by SQL, it is advisable to include all non-aggregated columns from your SELECT clause in your GROUP BY clause. Slick comes with a Scala-to-SQL compiler, which allows a sub-set of the Scala language to be compiled to SQL queries. Also available are a subset of the standard library and some extensions, e.g. for joins.

The fact that such queries are type-safe not only catches many mistakes early at compile time, but also eliminates the risk of SQL injection vulnerabilities. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement.
You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used. In PostgreSQL, the group by function can divide the rows generated by aggregate functions. The aggregate function is used to return a single result from multiple rows. There are many aggregate function like SUM(), COUNT(),MIN(), MAX(). The PostgreSQL GROUP BY clause can divide the rows returned from the SELECT statement into groups. For each and every group, we can apply an aggregate function like the SUM function to calculate the sum of items or the COUNT function to get the number of items in the groups.

WITH CUBE modifier is used to calculate subtotals for every combination of the key expressions in the GROUP BY list. WITH ROLLUP modifier is used to calculate subtotals for the key expressions, based on their order in the GROUP BY list. Sometimes we may require to add group by with multiple columns, if we have mysql query then we can do it easily by using sql query.

But if you want to give multiple columns in groupBy() of Laravel Query Builder then you can give by comma separated values as bellow example. When you're working with aggregate functions in SQL, it is often necessary to group rows together by common column values. Following each set of product rows for a given year and country, an extra super-aggregate summary row appears showing the total for all products. In my code here I first created and populated a table named NullGroupBy. The first and last rows have a value of NULL from the OrderDate, and the other two columns have different OrderDate values. As you can see by reviewing the output above, SQL Server rolls-up the two rows that contain a NULL OrderDate into a single summarized row.

In my example above, my GROUP BY clause controlled what column was used to aggregate the AdventureWorks2012.Sales.SalesOrderDetail data. In my example I summarize the data based on the CarrierTrackingNumber. When you group your data the only columns that are valid in the selection list are columns that can be aggregated, plus columns used on the GROUP BY clause. In my example I aggregated the LineTotal amount using the SUM function. For the aggregated value I set a column alias of SummarizedLineTotal.
You can compose queries using Metabase's graphical interface to join tables, filter and summarize data, create custom columns, and more. And with custom expressions, you can handle the vast majority of analytical use cases, without ever needing to reach for SQL. In this power bi tutorial, we learned power bi sum group by multiple columns. And also we discussed the below points power bi sum group by two columns using power query. The GROUP BY statement is often used with aggregate functions (COUNT(),MAX(),MIN(), SUM(),AVG()) to group the result-set by one or more columns. The columns that appear in the GROUP BY clause are called grouping columns.
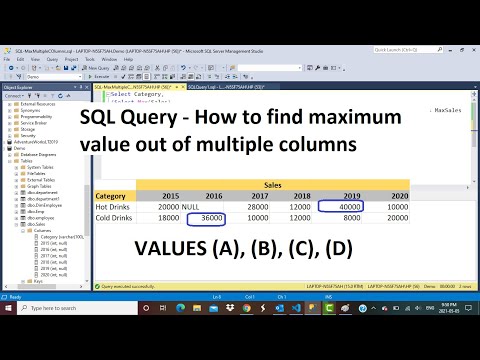
Can You Group By Two Columns In Sql If a grouping column contains NULL values, all NULL values are summarized into a single group because the GROUP BY clause considers NULL values are equal. We will use the employees and departments tables in the sample database to demonstrate how the GROUP BY clause works. However, MySQL enables users to group data not only with a singular column for consideration but also with multiple columns. We will explore this technique in the latter section of this tutorial.
We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query. There can be single or multiple column names on which the criteria need to be applied. We can even mention expressions as the grouping criteria. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause.

Note that multiple criteria of grouping should be mentioned in a comma-separated format. The GROUP BY clause permits a WITH ROLLUP modifier that causes summary output to include extra rows that represent higher-level (that is, super-aggregate) summary operations. ROLLUPthus enables you to answer questions at multiple levels of analysis with a single query.
For example, ROLLUP can be used to provide support for OLAP operations. GROUP BY is the command that can trip up many beginners, as it is often possible to have a SQL statement with the correct GROUP BY syntax, yet get the wrong results. A good rule of thumb when using GROUP BY is to include all the non-aggregate function columns in the SELECT statement in the GROUP BY clause. In the above query, the ISNULL function is used to display UNKNOWN for the NULL values and the GROUPING function is used to display ALL for the aggregate columns. Since NULL Values do not exist in the selected dataset, there will not be any difference to that output that you observed before.

Use the WITH clause to encapsulate logic in a common table expression . Here's an example of a query that looks for the products with the highest average revenue per unit sold in 2018, as well as max and min values. HAVING clause's key advantage is its ability to filter GROUPS using aggregate functions.

This is something you cannot do withing a SELECT statement. GROUP BY enables you to use aggregate functions on groups of data returned from a query. You can however not add operators operating on queries using database functions.

The Slick Scala-to-SQL compiler requires knowledge about the structure of the query in order to compile it to the most simple SQL query it can produce. It currently couldn't handle custom query operators in that context. An example for such operator is a MySQL index hint, which is not supported by Slick's type-safe api and it cannot be added by users. A GROUP BY clause can include multiple group_expressions and multiple CUBE|ROLLUP|GROUPING SETSs.

GROUPING SETS can also have nested CUBE|ROLLUP|GROUPING SETS clauses, e.g. GROUPING SETS(ROLLUP, CUBE), GROUPING SETS(warehouse, GROUPING SETS(location, GROUPING SETS(ROLLUP, CUBE))). CUBE|ROLLUP is just a syntax sugar for GROUPING SETS, please refer to the sections above for how to translate CUBE|ROLLUP to GROUPING SETS. Group_expression can be treated as a single-group GROUPING SETS under this context.